





LGBTQ+ history has often been hidden away. But we can bring that history out into the open–and you can play a part!
The Issue
The UWM Libraries house important archives holding historical and contemporary LGBTQ+ materials. Included are rich records of LGBTQ+ communities in Milwaukee, Wisconsin, and the Midwest generally. Not only do these archives contain textual documents such as community newsletters, advocacy group records, and personal letters–they also contain audiovisual materials. Examples include local television news and radio broadcasts, early LGBTQ+ community cable programming, and videorecorded oral histories.
Working with archives is fascinating, because these are primary sources that can be full of surprises. Reading and listening, the researcher makes new discoveries: a handwritten note on a news clipping might yield new insights A recording of an old news broadcast on high schools opening might make a surprising quick reference to a new student Gay-Straight Alliance having formed.
But what makes archival research fascinating is also what makes it frustrating, because often a user will have little idea of what is in the archive. Some textual sources like newspapers may have been digitized and processed using “OCR”–Optical Character Recognition–so you can use search terms to find materials you are interested in. But what about audiovisual materials? The UWM Library archives contain many digitized videos and audio recordings that users can access, but obviously they can’t just be run through a text-recognition package to be able to search their content. So those using the audiovisual archives have had to rely on the terse descriptions each item was given when it was added to the collection, which necessarily only provide a broad outline of the actual contents of the item.
The Solution
This is where the LGBTQ+ Audio Archive Mining Project comes in. Members of this project team are developing ways to automatically generate searchable text transcripts of the audiovisual materials in the archive. More than this: the team is using open-source software to create tools that will allow users like you to visualize patterns across the texts, such as how often various words appear, and relationships between terms that get used.
The end goal is that users will be able to search for terms that interest them–like “bisexual” or “domestic partner”–in novel places, like recordings of local news broadcasts not labeled as containing LGBTQ+ content. Users can find out how selected terms may have been used differently in the same timeframe in different contexts–were mainstream local news broadcasts mostly using the term “homosexual” at a time when community news sources were using “lesbian and gay”? A researcher could trace the uneven fading from usage of terms like “transvestite” alongside the growing usage of terms like “transgender”. And a user can trace the relationships between words. Are terms for LGBTQ+ people appearing in close proximity to terms identifying people of color? How does this change over time?
The LGBTQ+ Audio Archive Mining Project aims to allow academic researchers and community members to discover new information about LGBTQ+ history. It also aims to make the tools it is creating–and the processes for developing them–available to all, so that they can be used to mine information about other communities, in other archives.
Project Leads: Ann Hanlon, Head, Digital Collections & Initiatives and Digital Humanities Lab, UWM Libraries; Dan Siercks, Interim Director, Web & Data Services, UWM College of Letters & Science
Disciplinary Scholar: Cary Costello, Associate Professor, Department of Sociology and Director, LGBT Studies Program, UWM College of Letters & Science
Senior Administrator: Marcy Bidney, Assistant Director of Libraries for Distinctive Collections and Curator of the American Geographical Society Library, UWM Libraries
Team: Shiraz Bhathena, Digital Archivist, UWM Libraries; Jie Chen, Application Specialist, UWM Libraries; Karl Holten, Information Systems Specialist, UWM Libraries and College of Letters & Science; Ling Meng, Digital Collections Librarian, UWM Libraries
ACT UP Milwaukee Records: Digital Collection | Finding Aid
Collection documents the history and activism of the Milwaukee chapter of ACT UP (AIDS Coalition to Unleash Power). It includes meeting agendas and minutes, newsletters, press releases, flyers and other ephemera, grant applications, financial reports, subject files, and videos relating to ACT UP Milwaukee demonstrations. The collection also contains documentation regarding the ACT UP Network, an information clearinghouse for ACT UP chapters across the United States and Europe. ACT UP Milwaukee administered the Network.
AIDS Resource Center of Wisconsin Records: Digital Collection | Finding Aid
Founded in 1985, the AIDS Resource Center of Wisconsin (ARCW) is a national model for providing comprehensive, integrated health and social services to HIV patients. The collection documents the development of ARCW from a small provider of limited social services to the largest provider of HIV-health care services in Wisconsin and the most comprehensive AIDS service organization in the United States. It includes administrative records relating to governmental advocacy, annual reports, financial statements, strategic plans, board meeting minutes, and originating documents. It also contains photographs, posters, and audiovisual material related to the fight against HIV/AIDS in Wisconsin.
Cream City Foundation Records: Finding Aid
Founded in 1982, Cream City Foundation (CCF) is the only non-profit, grant making, community-based foundation serving the entire State of Wisconsin whose sole purpose is to support the changing needs of the lesbian, gay, bisexual and transgender (LGBT) communities. The collection contains correspondence, board meeting minutes, newsletters, financial information, publicity materials, articles of incorporation, and annual reports. It also contains grant applications from over eighty LGBT organizations, many of which are now inactive. These applications are likely the only surviving documentation of many of these groups. Examples of educational materials produced with CCF support are included in the collection.
Gay People’s Union Records: Digital Collection | Finding Aid
Collection consists of the records of the Gay Peoples Union (GPU), the first gay rights organization in Milwaukee, Wisconsin and one of the earliest such groups in the state. Collection documents the history of GPU from its beginnings as a University of Wisconsin-Milwaukee student organization to its development as the most important gay and lesbian rights organization in Milwaukee in the 1970s. The collection also includes audio recordings of Gay Perspective, a radio program produced by GPU and broadcast on local radio stations from 1971 to 1972, and other public presentations given by GPU members as part the organization’s educational mission.
James Liddy Papers: Finding Aid
The collection documents James Liddy’s life as a poet and professor. Liddy was born and raised in Ireland, and after briefly practicing law, he turned to a life of poetry. He moved to San Francisco in 1967 and began teaching poetry and English at various institutions across the U.S. before finally settling down at the University of Wisconsin-Milwaukee in 1976, where he taught for over 30 years. The collection contains primarily correspondence, literary papers, and general files. Some of his works include: In a Blue Smoke (1964), Baudelaire’s Bar Flowers (1975), A White Thought in a White Shade (1987), Collected Poems (1994), and The Doctor’s House (2004).
Milwaukee Gay/Lesbian Network Records: Digital Collection | Finding Aid
Collection consists of regular and special programming produced by the Milwaukee Gay/Lesbian Cable Network (MGLCN) from 1987 to 1994. MGLCN was established by a group of individuals who wanted to produce regular programming on local gay and lesbian issues using the newly available facilities of MATA (Milwaukee Access Telecommunications Authority) Community Media. MGLCN produced Tri-Cable Tonight, a monthly news and entertainment program; the New Tri-Cable Tonight, a panel discussion program; and Yellow on Thursday, a comedy show featuring shorts, skits, and parodies.
Milwaukee PrideFest Records: Finding Aid
Milwaukee’s first Pride event occurred when the Gay Liberation Front (GLF) organized a “Gay Pride Week” in January 1971. The event was repeated in 1972 and 1973. While there were sporadic “gay days” and picnics in the late 1970s and 1980s, Milwaukeeans typically traveled to Chicago to observe or march in that city’s celebrations. However, Pride events were held in Milwaukee in both 1980 and 1981. The Milwaukee Lesbian/Gay Pride Committee (MLGPC) held its first annual pride event in 1988. In 1994 MLGPC was dissolved and PrideFest, Inc. was created. PrideFest has been held at various locations during its history, including Mitchell Park (1988), Cathedral Square Park (1989-1990), Juneau Park (1991-1993), Veterans Park (1994-1995), and the Henry Maier Festival Park (since 1996). The festival features a diverse range of performers and numerous activities such as a volleyball tournament, parade, religious ceremony, mass wedding/commitment ceremony, and fireworks.
Miriam Ben-Shalom Papers: Finding Aid
The collection contains personal papers and other documentation collected by Miriam Ben-Shalom, the first gay or lesbian member of the United States military service to be reinstated after being discharged for her sexual orientation. The collection documents Ben-Shalom’s legal battles with the military, as well as the general topic of homosexuals and the military. Other materials pertain to the gay and lesbian veterans movement, feminism, and related social justice issues.
Milwaukee LGBT Oral History Project: Digital Collection | Finding Aid
Collection consists of oral history interviews conducted by the Milwaukee LGBT History Project with members of Milwaukee’s LGBT (lesbian, gay, bisexual, and transgender) community. The collection includes audio records and interview transcripts. Interviewees describe their coming out experiences, the Gay Liberation Movement in Milwaukee, early LGBT organizations, the impact of feminism on LGBT politics, and LGBT social activities.
Milwaukee Transgender Oral History Project: Digital Collection | Finding Aid
Interviews with eight individuals concerning Milwaukee’s transgender community and its history. Among them are social activists, organizational leaders, healthcare workers, service providers, and performers. Individuals self-identify across a broad spectrum of gender identities, and some resist gender identification entirely. Topics covered include transgender people and the feminist movement, the intersection of transgender identity and sexual orientation, transgender healthcare, coming out, and community organizations.
Ray Vahey Papers: Finding Aid
The Ray Vahey papers document Vahey’s life with his partner, Richard Taylor, and their political activism on behalf of gay, lesbian, bisexual, and transgender civil rights in Wisconsin.
Shall Not Be Recognized Exhibition Records: Digital Collection | Finding Aid
Materials regarding the Shall Not Be Recognized: Portraits of Same-Sex Couples exhibit, which documents the experiences of thirty same-sex couples in long-term, committed relationships in the area of Milwaukee, Wisconsin. The traveling exhibit was a collaboration between author Will Fellows and photographer Jeff Pearcy.
Final Deliverables
The LGBTQ+ AV Archive Mining Project closed on October 26, 2021. The final deliverables, including the R dashboard and transcripts, can be found here:
- Dashboard: http://ls-shiny-prod.uwm.edu/collections_as_data/code/rshiny_dashboard/
- Transcripts: https://dc.uwm.edu/lgbtq/
- Github repository: https://github.com/UWM
- Final report: https://osf.io/pjes7
Building a dashboard
Work on our speech-to-text workflow progressed through fall 2020, with a shift from the open source Mozilla DeepSpeech, to experimentation with Microsoft Azure’s Speech-to-Text services. Given the immediate improvements in accuracy – including a lower error rate for community-identified terms – we have been using the Azure workflow as our primary method for text extraction since December 2020. More on continued “error identification” in a later post!
With the creation of an initial corpus of text from our LGBTQ+ AV materials, we began work on a dashboard to provide a path for future users to search and access the transcripts, as well as do some cursory analysis of the corpus itself. And because we want to create an overall model that is easily replicated in a variety of settings, we began by using an existing dashboard package for R called corporaexplorer. The corporaexplorer package enabled us to quickly set up a working dashboard that provided search term filtering, multiple-term comparisons, a document map, a timeline, and heat maps to show the concentration of a term in a single object and across collections.

Additionally, we wanted to ensure the data search and visualization tools were sufficiently straightforward for students and community members to use, and that they accurately represented the occurrences of pertinent LGBTQ+-related terms. To test the tools, we pulled together a small group of researchers with knowledge of LGBTQ+ history who we expect will also derive some benefit from the data sets and tools themselves, for both teaching and research. Their feedback prompted us to review the accessibility of our dashboards, improve item-level metadata, and investigate how we can enable researchers to incorporate related data sets from other collections alongside our own. More on an improved dashboard in a later post!
Note: The pilot dashboard is available here: http://10.60.50.144/corpus/. However, the link will work only if you are at UWM or connected via UWM VPN (as of May 2021).
Speech-to-Text Workflows and DeepSpeech
There are several parts to our project – all important and all intertwined. To help make sense of our updates, I’ll try to tag them according to their most prominent feature in terms of speech-to-text progress, community engagement, professional development, and LGBT collections. To kick things off – an update on how things have progressed and where things stand in our speech-to-text processes. The good news is we have made progress! And here’s how:
Our goal is to extract meaningful text transcripts from the hundreds of hours of archival AV materials that are part of our LGBT collections in the UWM Archives. This includes oral history interviews, cable access shows dedicated to LGBT life in Milwaukee that debuted in the 1980s and 1990s, local radio programs from the same era, and news segments from Milwaukee’s local mainstream news media. It’s important that the text we extract is accurate enough to enable meaningful research. That means that language used by and about the LGBT community is especially important to capture accurately. In a later post we’ll talk more about the issues raised by use of terms that are considered outdated and even offensive – an extremely important topic when we are considering how to make these data sets and the archival materials themselves publicly accessible. For now, we’ll concentrate on getting the text out in the first place:
The project is using a publicly licensed speech-to-text engine, Mozilla’s DeepSpeech. It is “pre-trained” using the Mozilla Common Voice dataset. The code is open, so the model can be further trained locally, to make up for deficits in the Common Voice dataset or to fine-tune (within reason) to a particular collection of AV. We’re using DeepSpeech for all of the above reasons, and in order to develop a model that will work especially effectively with the archival AV materials that exist across the LGBTQ+ collections in the UWM Archives.
Throughout the summer, Dan Siercks worked with DeepSpeech to augment the model in order to raise our confidence that the transcripts would recognize expected language that the Milwaukee LGBTQ community might use to describe themselves and their experiences. Cary Costello, our Disciplinary Scholar and UWM’s Director of LGBT Studies, created a “terminology list” split into contemporary and historic LGBTQ+ terms, with each divided into tiers from most generic/mainstream to the most narrow used by specific subcommunities.
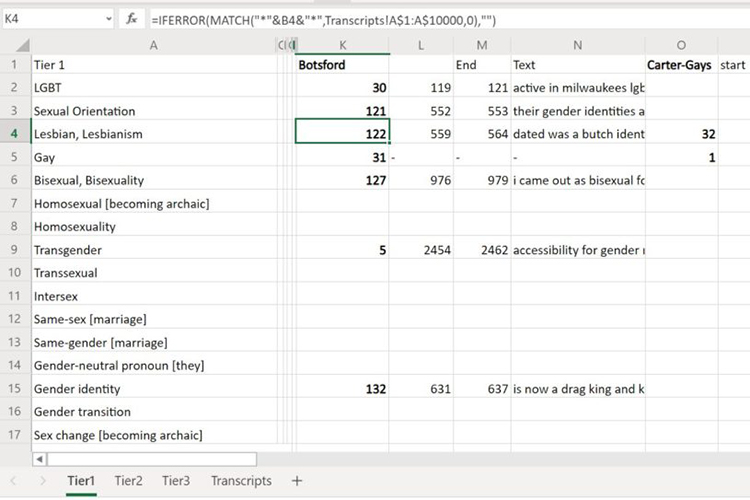
Using a local test collection that included oral histories with human-created transcripts, Dan developed a script to identify terms from Cary’s list in our test collection transcripts. We then manually identified start-and-stop times (made even easier because these transcripts have been coded using OHMS) and dropped those criteria into a spreadsheet. Using Audacity, Dan was able to create a simple process to locate and “snip” those audio snippets from the recordings to create a test data set that emphasized the LGBTQ+ terms we want our model to more reliably identify. While this approach needs to be carefully calibrated in order to avoid overcorrecting the model, we have found that our data sets have improved accuracy. We believe this is due to the term-specific augmentation, having run multiple iterations of the model, and a significant improvement in the model itself following an upgrade that we recently implemented locally.