Why Wikidata is Good for Yiddish Theatre Research

Part I of this series can be read here.
Knowledge is not data; it is what you do with the data. One tool for doing something with that data is the free and open Wikidata software, which is licensed under Creative Commons. Wikidata is thus ideally placed to serve as the foundation for a Yiddish Theatre/Performing Arts finding aid and as a source of free and reusable data. Wikidata provides many tools to researchers to help them discover and visualize relationships that previously remained sealed or scattered among static information resources on the Yiddish theatre. For all Jewish studies disciplines, one of Wikidata’s great strengths is its multilingual capabilities with regard to names and identifiers. Consider the Polish Jewish actor Jakub Rajnglas, for example. Wikidata-driven applications have different ways of representing names across several languages and scripts, and allow users to search for a name by the one with which they are most familiar. In this case, a user could search for Jakub Rajnglas, Jacob Reinglass, Yankev Raynglas, James Rajnglas, יעקב ריינבלאס, or Яков Рейнглас. Through crowdsourcing, anyone can create, use, edit and download data from Wikidata. The more accessible and downloadable these data are, the more possibilities there will be for both scholars and more casual users to sort, manipulate and analyze the data in ways that apply to their research.
Wikidata: What It Looks Like
Some tools appear on every page in Wikidata. On the left side of each Wikidata page is a “tool-box” containing useful scripts for working with Wikidata. One of these is “Reasonator,” which enhances the user interface of an individual Wikidata page.
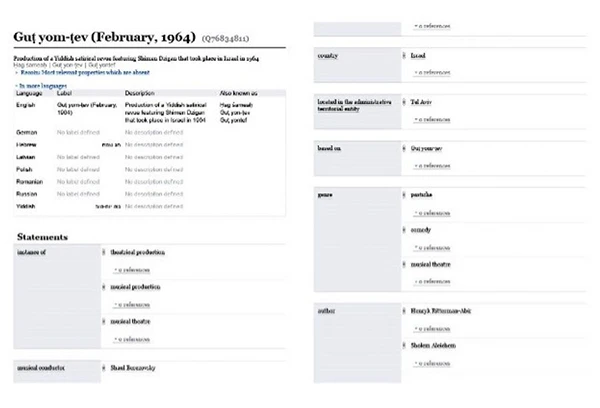
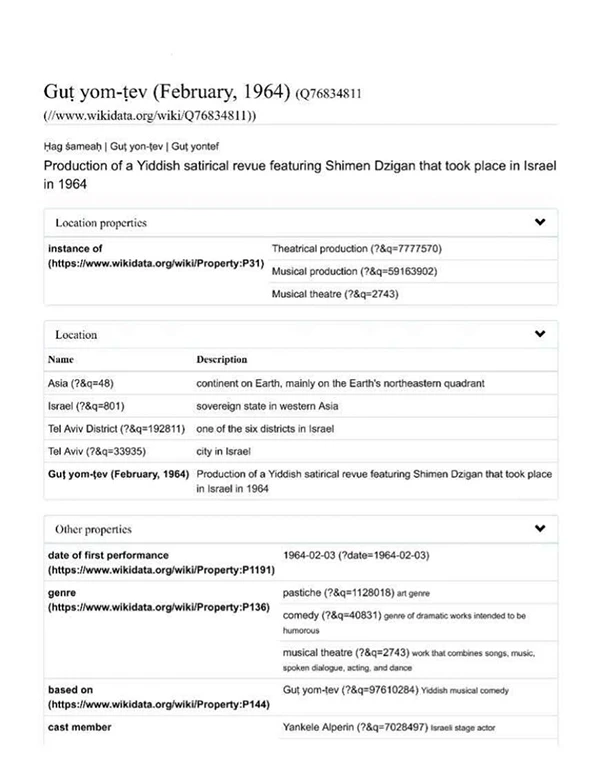
Consider these two representations of the same Wikidata item for a production of the Yiddish satirical revue Gut yontev that was performed in Tel Aviv, Israel in February 1964. What we see in the image above is a group of statements providing “structured”1 information on this production. The image below is what happens when the output is “reshaped” using Reasonator. Reasonator transforms Wikidata into what I call “Wikidata in pretty.” This tool enables a restructuring of information that transforms them almost into articles—in any language. These closely resemble the Info boxes often found next to articles on Wikipedia and Google.
Another Wikidata tool—“What links here”—enables users to see a list of pages that link to the current one, as we see here on the Wikidata page for Shimon Dzigan.

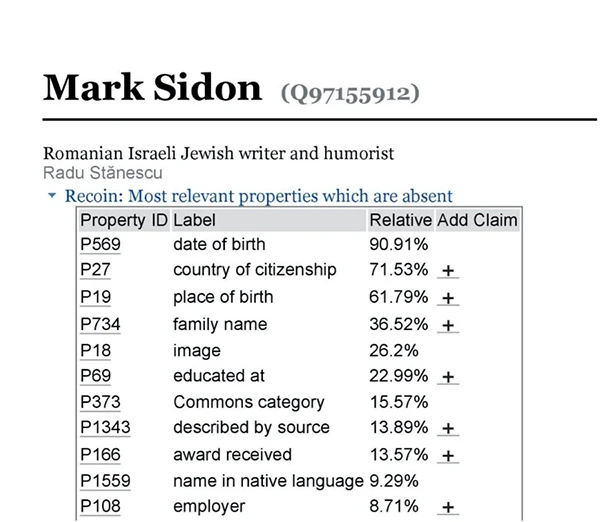
Recoin (Relative Completeness Indicator) is a tool found on every Wikidata page that determines the “completeness” of an individual item and will recommend additional properties to enhance the value of the existing information. By looking at the icon in the right-hand corner, we see that the Wikidata page for the Romanian satirist Mark Sidon contains minimal information. In the left-hand corner, Recoin has generated a list of suggested properties than can be added to provide additional information.
Additional community-developed tools for enhancing the utility of the data include :
1) “Wikidata visualization” provides easy-to-configure tools for displaying the results of Wikidata queries generated using the SPARQL query language.2 In the image at the head of the article, for example, we have a graph that contains all values related to the productions and performances represented in the collection. The graph enables researchers to discover previously unknown relationships among disparate sources: https://query.wikidata.org/.
2) “Cradle” is a tool that enables users to generate new Wikidata items. These template-like forms are user-generated, and based on classes of things like actors, authors, books, journals, paintings, and hotels. The forms consist of fields that represent statements on Wikidata: dates of birth, names, locations, any relevant information that can describe a new item. All of the fields generally correspond to a property on Wikidata. As of this publication, there are just over 100 forms on Cradle. Currently, very few of these are related to theatre studies. Users can contribute to adding new forms on the Wikidata Project:Cradle page.
3) “VizQuery” enables people to create simple queries in Wikidata without needing to engage with the Sparql querying language.
When I began thinking about this project, I knew next to nothing about navigating or moving around Wikidata. I had to learn while doing, and the data that I created were uploaded manually. But when contributing data from an existing external source, data will need to be batch uploaded. There are several tools for “ingesting” large amounts of data into Wikidata. Most projects of a significant size will depend on tools like OpenRefine, Mix ’n’ Match, and QucikStatements.
A number of tools also exist for working with Google spreadsheets, csv files, and Excel spreadsheets. These can be found on GitHub.
Taking it forward
I am excited when I look ahead. A central repository that provides information on the international heritage of the Yiddish theatre is not impossible to conceive. Connecting databases, websites and other information repositories, creating individual records that can be all searched in one place while taking advantage of shared expertise is within our reach. Wikidata enables us to connect disparate sources about actors, playwrights, librettists, scenographers, choreographers, musicians, productions, plays, and musicals that are the Yiddish theatre. Wikidata means that we will all benefit from the knowledge and research of our colleagues, institutions, and communities.
Notes
- Structured data is a way of describing a website or webpage to make it easier for search engines to understand, https://yoast.com/what-is-structured-data.
- Sparql is a semantic query language for databases developed by the World Wide Web Consortium (W3C), https://www.w3.org/TR/rdf-sparql-query/.
Article Author(s)
